Xinghui Li
I am an AI Scientist from Mistral AI. I obtained my PhD from the Active Vision Lab of the University of Oxford
supervised by Professor Victor Adrian Prisacariu .
I took my undergraduate studies at University of Oxford as well and received Master of Engineering with First Class Honour.
My research interest includes 3D computer vision, generative models amd multimodal LLM.
Email /
CV /
Google Scholar /
Linkedin
Recent News
• Our survey in semantic correspondence is accepted by TPAMI.
• I joined Mistral AI as an AI Scientist in London.
Projects
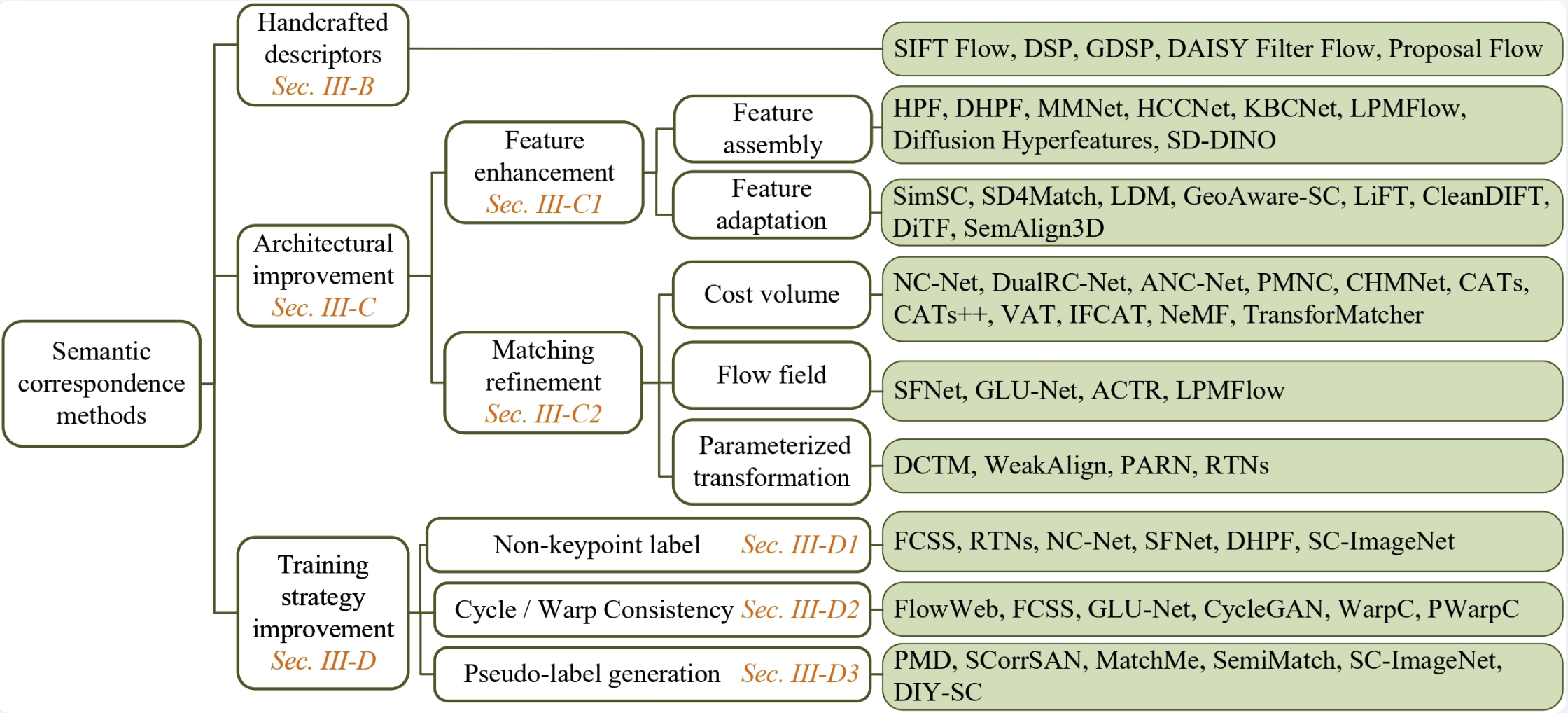
Semantic Correspondence: Unified Benchmarking and a Strong Baseline
Xinghui Li ,
Jingyi Lu,
Kai Han
TPAMI , 2025
project page
/
paper
/
code
An extensive survey of semantic correspondence methods with a unified benchmark and a strong baseline achieving state-of-the-art performance.
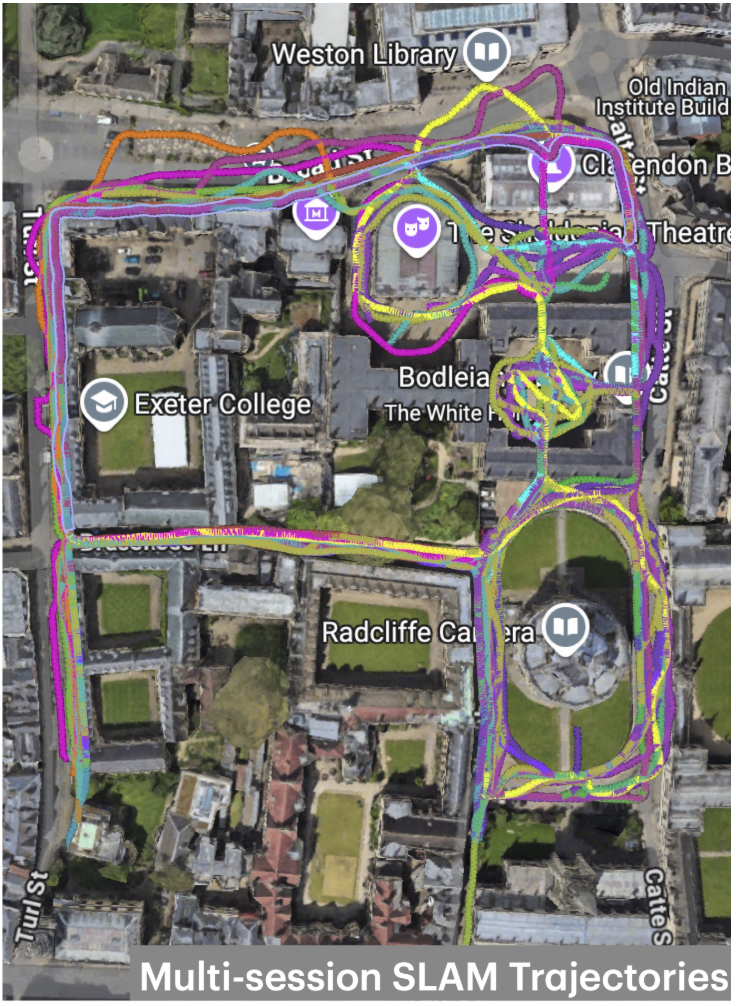
Seeing in the Dark: Benchmarking Egocentric 3D Vision with the Oxford Day-and-Night Dataset
Zirui Wang *,
Wenjing Bian *,
Xinghui Li *,
Yifu Tao ,
Jianeng Wang,
Maurice Fallon ,
Victor Adrian Prisacariu
NeurIPS , 2025
project page
/
paper
/
data
/
video
A large-scale egocentric dataset capturing over 30 km of trajectories across five Oxford locations for benchmarking 3D vision under extreme illumination changes.
RegionDrag: Fast Region-Based Image Editing with Diffusion Models
Xinghui Li ,
Kai Han ,
ECCV , 2024
project page
/
paper
/
code
A fast and versatile region-based image editing method.
Your browser does not support the video tag.
Your browser does not support the video tag.
GaussCtrl: Multi-View Consistent Text-Driven 3D Gaussian Splatting Editing
Jing Wu *,
Jia-Wang Bian *,
Xinghui Li ,
Guangrun Wang ,
Ian Reid ,
Philip Torr ,
Victor Adrian Prisacariu
ECCV , 2024
project page
/
paper
/
code
Text-driven multiview-consistent 3D Gaussian Splatting Editing through depth control and attention alignment.
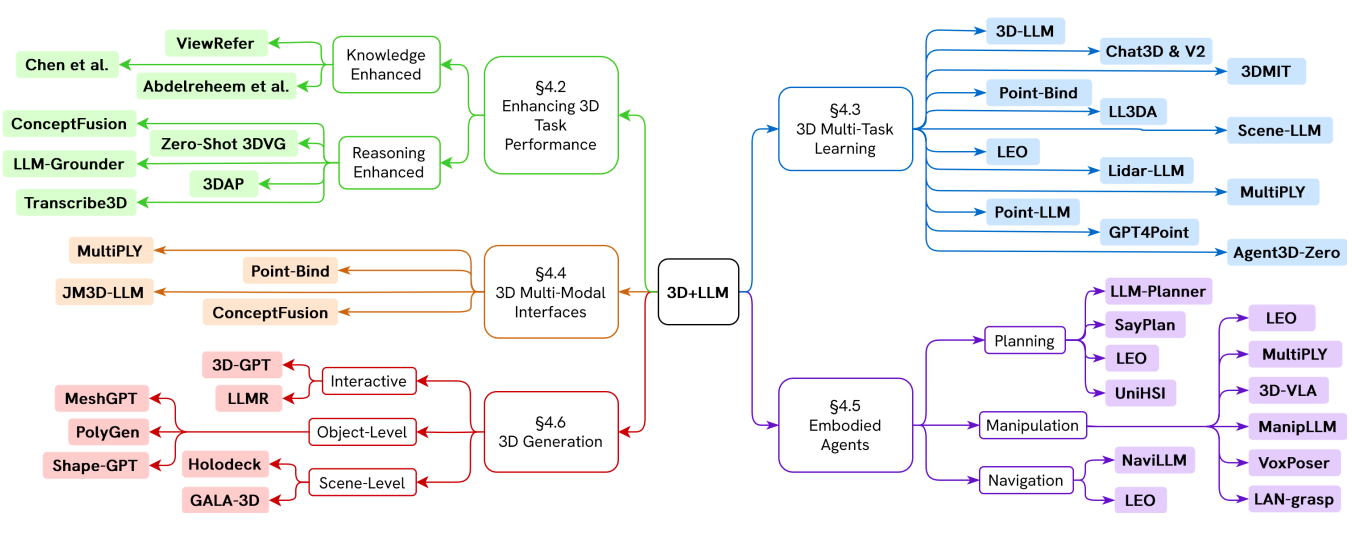
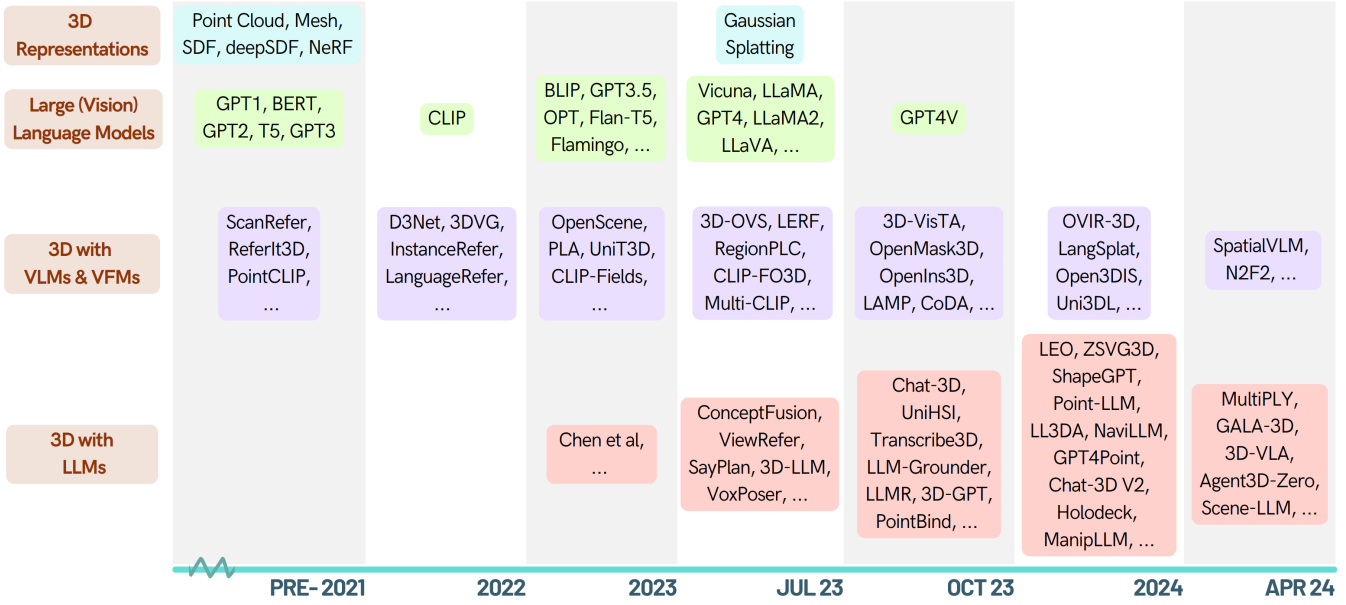
When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models
Xianzheng Ma *,
Yash Bhalgat *,
Brandon Smart *,
Shuai Chen ,
Xinghui Li ,
Jian Ding ,
Jindong Gu ,
Dave Zhenyu Chen ,
Songyou Peng ,
Jia-Wang Bian ,
Philip Torr ,
Marc Pollefeys ,
Matthias Nießner ,
Ian Reid ,
Angel X. Chang ,
Iro Laina ,
Victor Adrian Prisacariu
ArXiv , 2024
project page
/
paper
A survey paper that provides a comprehensive overview of the methodologies enabling LLMs to process, understand, and generate 3D data.
Your browser does not support the video tag.
Neural Refinement for Absolute Pose Regression with Feature Synthesis
Shuai Chen ,
Yash Bhalgat ,
Xinghui Li ,
Jiawang Bian ,
Kejie Li ,
Zirui Wang ,
Victor Adrian Prisacariu
CVPR , 2024
project page /
paper /
code /
author bios
A post-process for refining generic APRs using neural feature fields.
SD4Match: Learning to Prompt Stable Diffusion Model for Semantic Matching
Xinghui Li ,
Jingyi Lu,
Kai Han ,
Victor Adrian Prisacariu
CVPR , 2024
project page /
paper /
code
Enhancing the discriminative power of Stable Diffusion on semantic matching by prompt tuning.
DualRC: A Dual-Resolution Learning Framework With Neighbourhood Consensus for Visual Correspondences
Xinghui Li ,
Kai Han ,
Shuda Li ,
Victor Adrian Prisacariu
TPAMI , 2023
paper /
code
A flexible framework to learn both geometric and semantic matching.
SimSC: A Simple Framework for Semantic Correspondence with Temperature Learning
Xinghui Li ,
Kai Han ,
Xingchen Wan ,
Victor Adrian Prisacariu
ArXiv , 2023
paper
A simple temperature learning framework that enables accurate semantic matching using feature backbone only.
Your browser does not support the video tag.
DFNet: Enhance Absolute Pose Regression with Direct Feature Matching
Shuai Chen ,
Xinghui Li ,
Zirui Wang ,
Victor Adrian Prisacariu
ECCV , 2022
project page /
paper /
code
Leveraging luma-prior NeRF and direct feature matching to enhance 6-DoF camera pose regression approaches.
Your browser does not support the video tag.
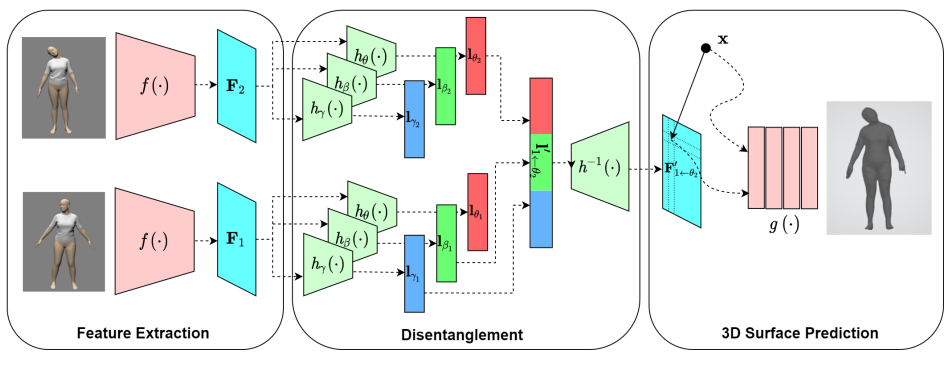
Disentangling 3D Attributes from a Single 2D Image: Human Pose, Shape and Garment
Xue Hu *,
Xinghui Li *,
Benjamin Busam ,
Yiren Zhou ,
Ales Leonardis ,
Shanxin Yuan
BMVC , 2022
paper
A 2D-to-3D disentanglment framework that learn pose, shape and garment attributes of a dressed human.
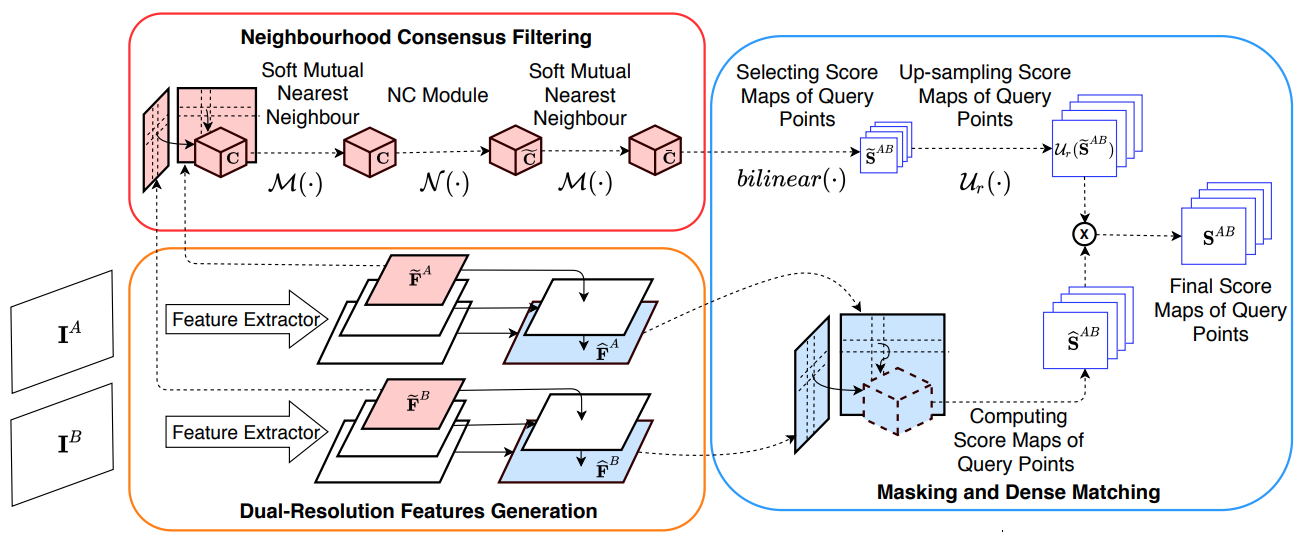
Dual-Resolution Correspondence Networks
Xinghui Li ,
Kai Han ,
Shuda Li ,
Victor Adrian Prisacariu
NeurIPS , 2020
project page /
paper /
code
A dual-resolution network that adapts 4D neighbourhood consensus filtering to high-resolution images.
Academic Services
Conference Reviewer: CVPR 2023, 2024; ICCV 2023, 2025; ICML 2025; ECCV 2024; NeurIPS 2024, 2025; AAAI 2023, 2024
Journal Reviewer: TIP 2023, 2024; TMLR
Awards: ICML 2025 Outstanding Reviewer